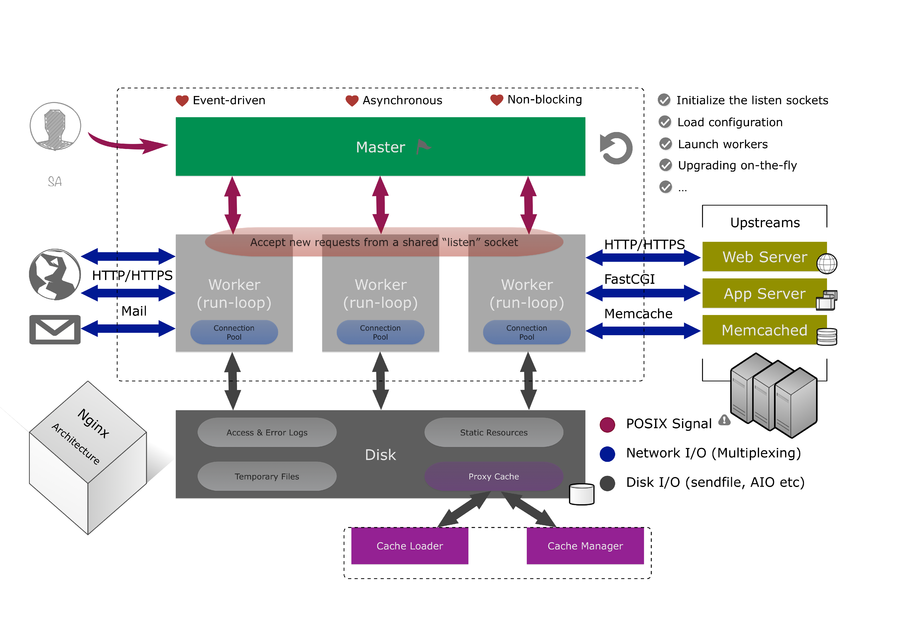
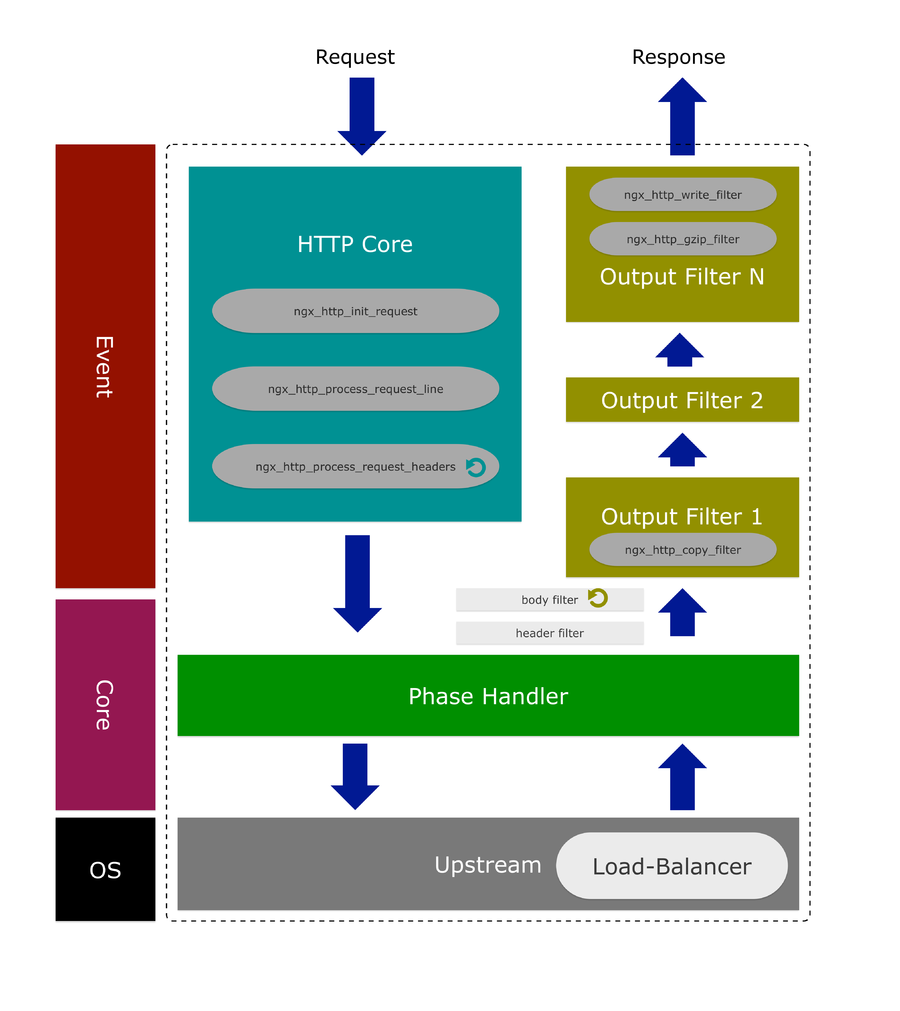
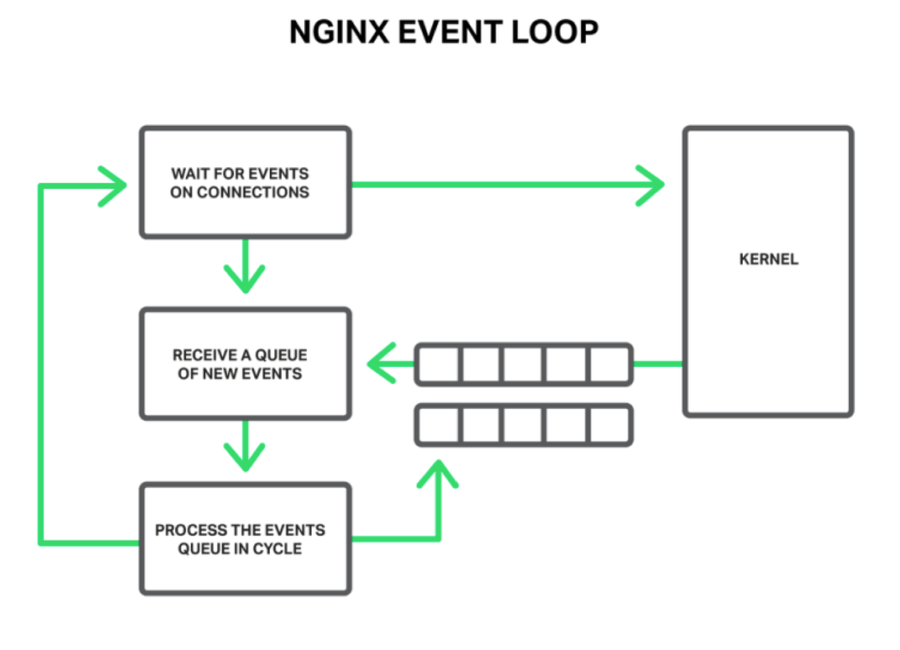
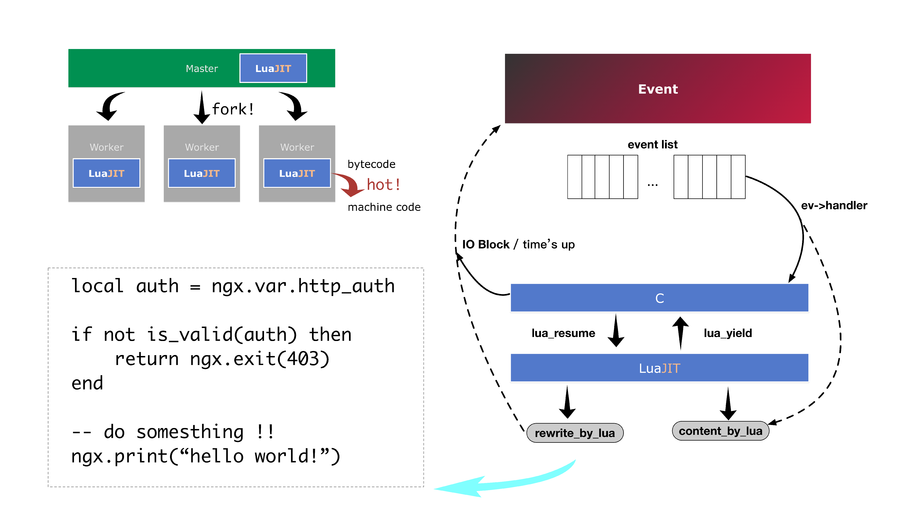
引子
过度优化 - volatile
编译器优化
1
2
3
4
5x= 0
Thread1 Thread2
lock(); lock;
x++; x++;
unlock(); unlock();变量缓存在寄存器而不写回
cpu 动态调度换序
1
2
3
4x = y = 0;
Thread1 Thread2
x= 1; y = 1;
r1 = y; r2 = x;1
2
3
4x = y = 0;
Thread1 Thread2
r1 = y; y = 1;
x1 = 1; r2 = x;编译器指令顺序交换
过度优化 - barrier
1 | volatile T* pInst = 0; |
c++ 的 new 对象是分 2 个步骤:
- 分配内存
- 调用构造函数
pInst = new T 包含了 3 个步骤:
- 分配内存
- 在分配内存上调用构造函数
- 将内存地址复制给 pInst
而步骤 2 和步骤 3 是可以交换的,导致的问题是分配的内存尚未调用构造函数就已经被分配出去
使用 lwsync 指令,防止编译指令换序
1 |
|
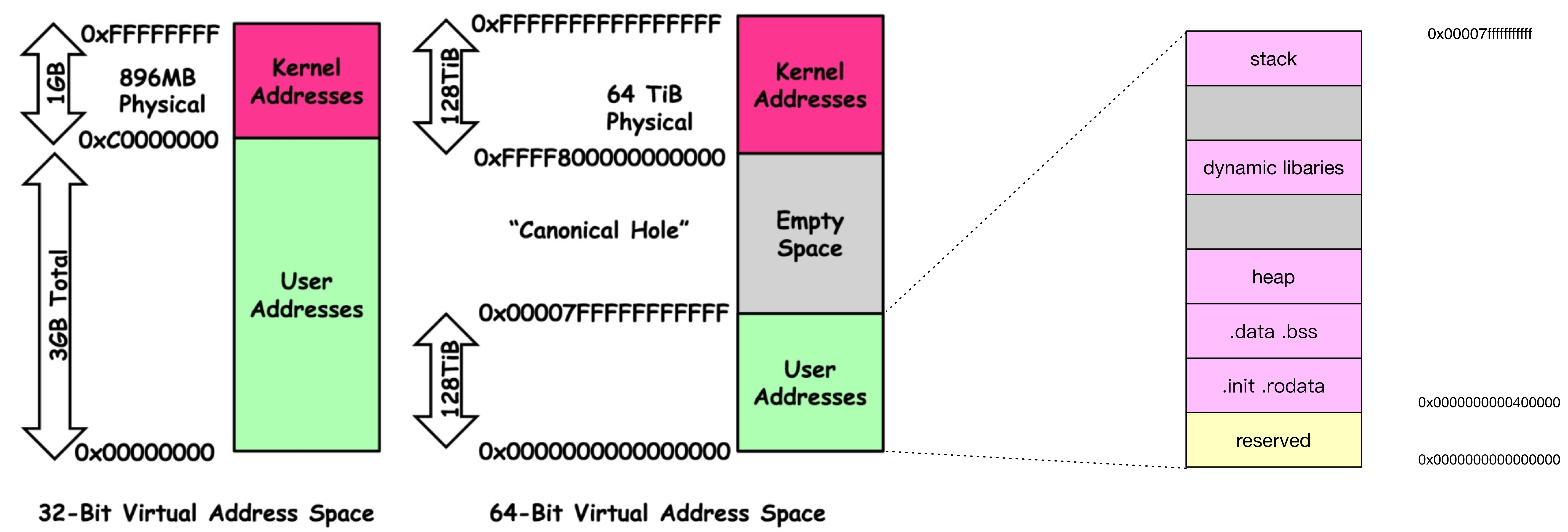
内存与装载
64 位内核虚拟地址和程序布局空间关系
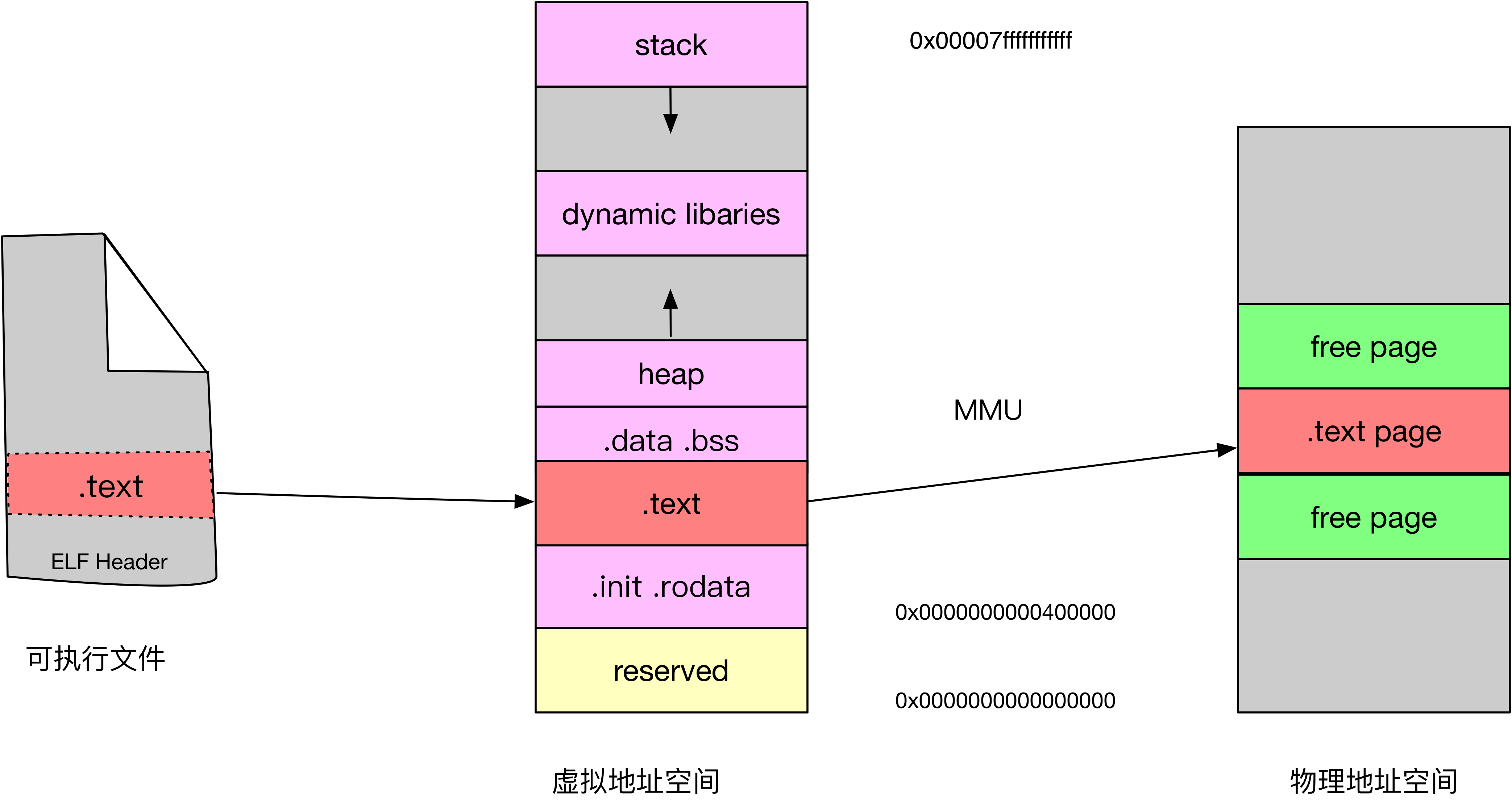
可执行文件,虚拟地址空间和物理地址空间的映射关系
进程堆管理
两种堆分配形式
- brk 系统调用,设置进程数据段的结束地址,向高地址移动,扩大的部分空间可以被程序使用(sbrk 对 brk 的包装)
- mmap 向操作系统申请一段虚拟地址空间,可以映射到某个文件,不映射文件时为匿名空间(用于 malloc)
调用惯例
函数调用方和被调用的约定
- 函数参数的传递顺序和方式(栈传递,寄存器传递;压栈顺序(左到右,右到左))
- 栈的维护方式,出栈由调用方还是被调用方
- 名字修饰策略
| 调用惯例 | 出栈方 | 参数传递 | 名字修饰 |
|---|---|---|---|
| cdecl | 函数调用方 | 从右至左 | 下划线+函数名 |
| stdcall | 函数本身 | 从右至左压栈 | 下划线+函数名+@+参数字节数,如 int func(int a, double b) -> _func@12 |
| fastcall | 函数本身 | 头两个字节放入寄存器,其他从右至左压栈 | @+函数名+@+参数字节数 |
| pascal | 函数本身 | 从左至右压入栈 | 较复杂 |
编译
- 预编译
- 编译
- 汇编
- 链接
预编译
预编译工作:宏展开,删除注释,生成行号和文件标识
1 |
|
1 | ~ gcc -E hello.c -o hello.i |
编译
- 词法分析
- 语法分析
- 语义分析
词法分析
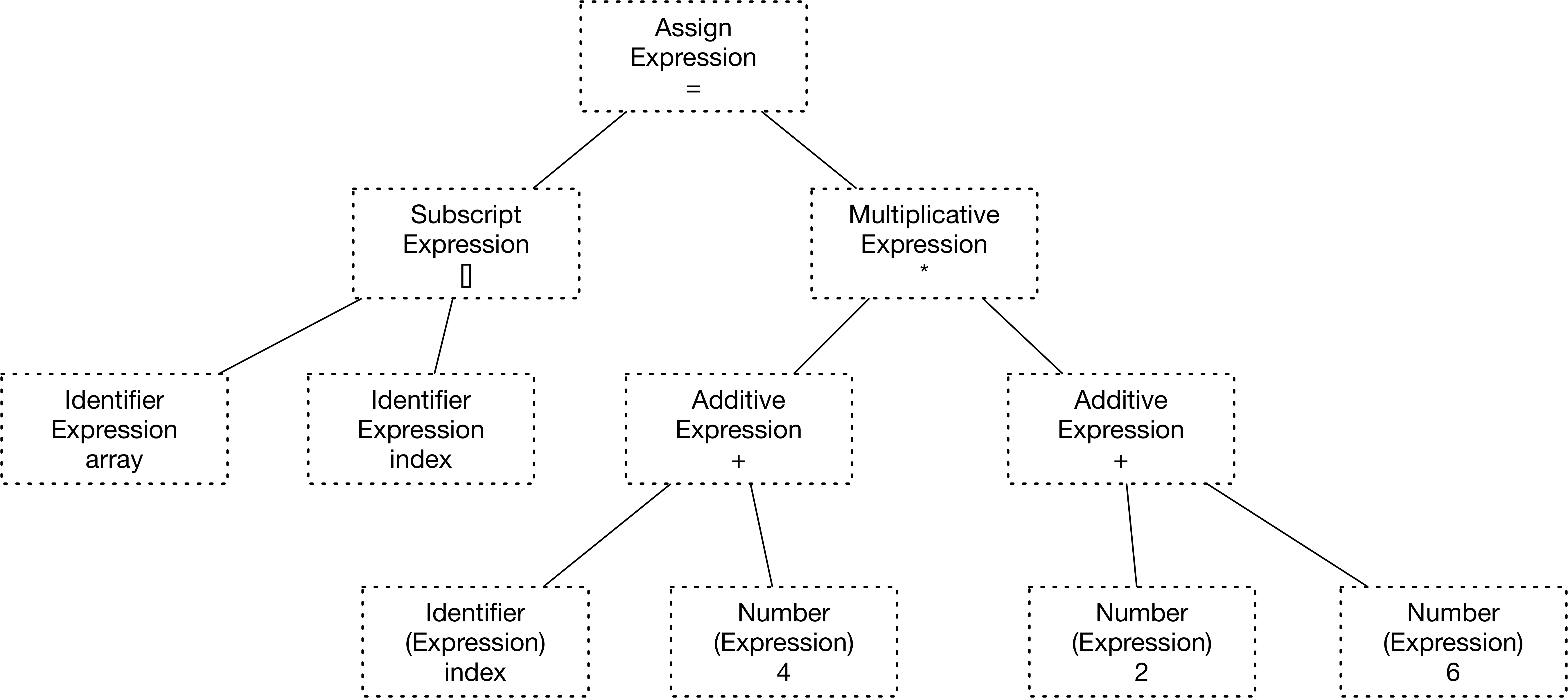
1 | array[index] = (index + 4) * (2 + 6) |
| symbol | array | [ | index | ] | = | ( | index | + | 4 | ) | * | ( | 2 | + | 6 | ) |
| type | 标识符 | 左方括号 | 标识符 | 右方括号 | 赋值 | 左圆括号 | 标识符 | 加号 | 数字 | 右圆括号 | 乘号 | 左圆括号 | 数字 | 加号 | 数字 | 右圆括号 |
语法分析
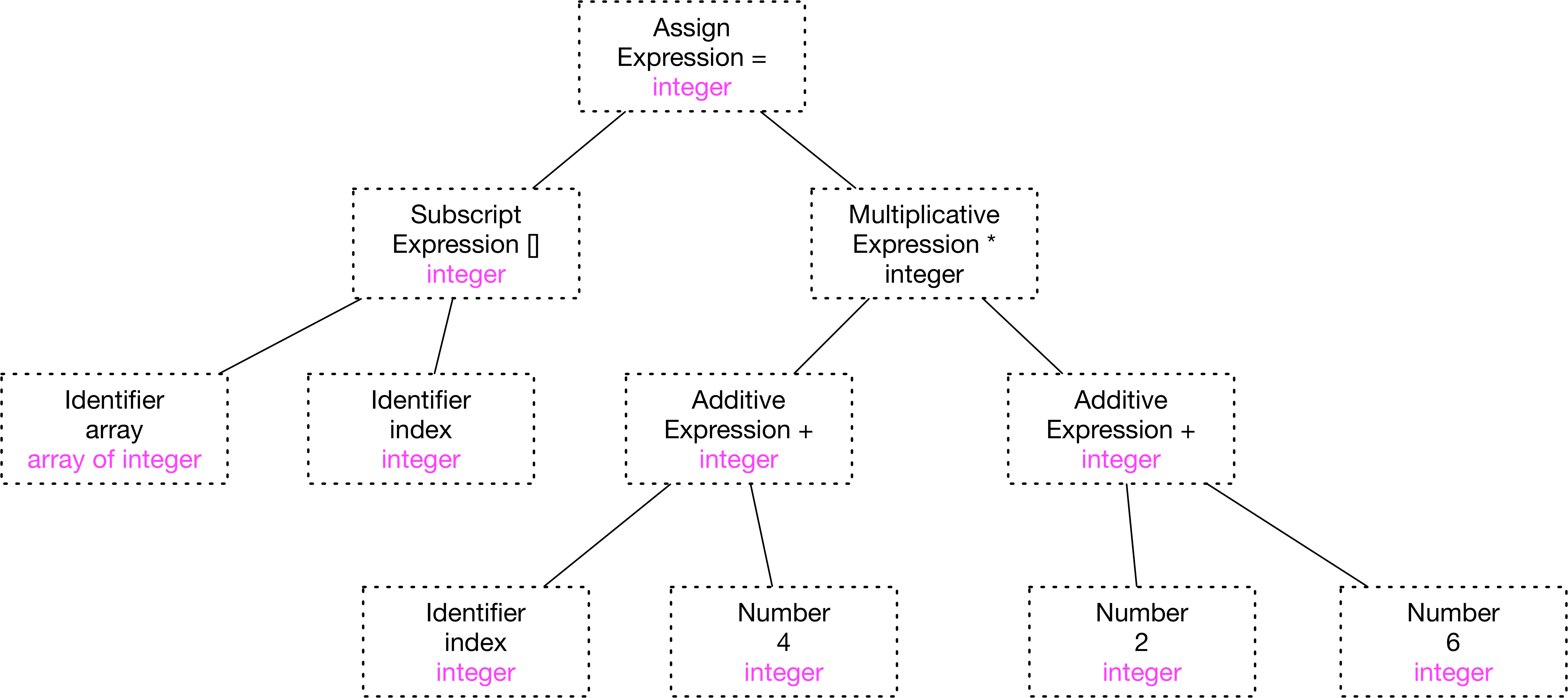
语义分析
汇编
汇编代码转换成机器指令(可理解为 2 进制)
链接
目标文件链接成可执行文件
- 地址和空间分配 - Address and Storage Allocation
- 符号决议 - Symbol Resolution
- 重定位 - Relocation
目标文件
目标文件类型
| 目标文件类型 | 含义 | 示例 |
|---|---|---|
| Relocatable File | 包含代码和数据,可链接为可执行文件或者共享目标文件,静态文件也属于这一类 | *.o |
| Executable File | 可执行文件 | /bin/bash |
| Shared Object File | 可以和其他重新可定位文件链接成新的共享文件;作为运行进程的映象一部分 | *.so |
| Core Dump File | 进程意外终止是的堆栈信息 | core dump |
目标内容
示例代码
1 | int printf(const char* format, ...); |
查看示例代码的 Sections 情况,因为还是目标文件,VMA 和 LMA 地址都是 0,需要在链接的时候确定,objdump 目标文件的一些常见 Section
1 | ~ objdump -w -h SimpleSection.o |
Sections 常见字段含义
| 字段 | 含义 |
|---|---|
| .text | 代码段 |
| .data | 数据段 |
| .bss | 未初始化的全局变量和静态变量 |
| .rodata | 只读数据段(只读字符串等, eg: “hello %s”) |
| .comment | 编译器版本信息 |
| .note.GNU-stack | 堆栈提示段 |
| .eh_frame | - |
目标文件段分布
使用 readelf 查看目标文件中的所有 Section
1 | vagrant@onepiece:~/tmp readelf -S SimpleSection.o |
静态链接
静态链接过程
1 | ~ gcc -c a.c |
1 | /* a.c */ |
段合并
合并多个目标文件中的相同 Section, 分配内存和虚拟地址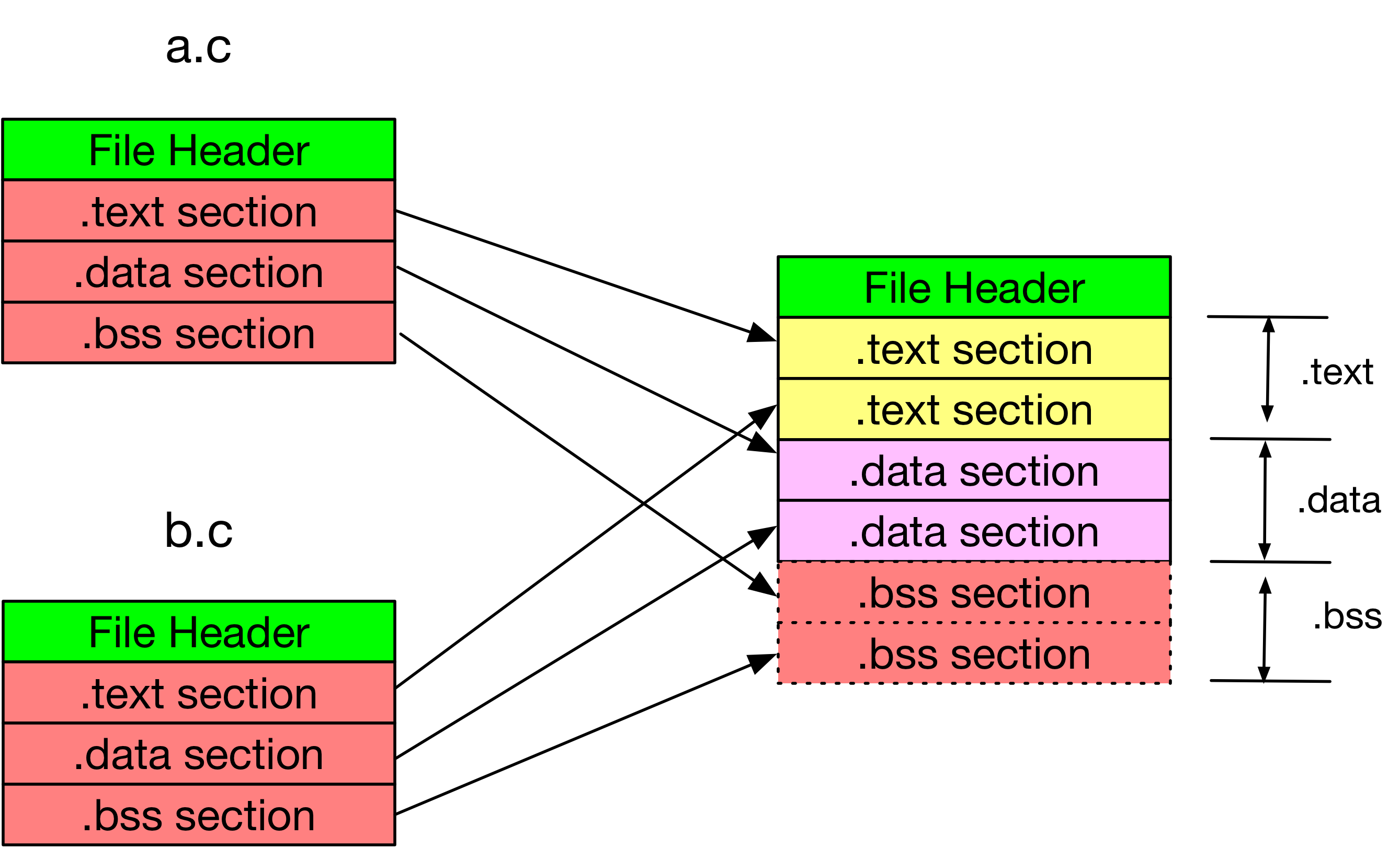
符号地址确定
单个目标文件中,每个 Section 的位置已确定,每条指令的 offset 也是固定的,在合并多个目标文件后,
将多个相同 Section 合并,调整对应 Section 中的 offset 得到 Section 合并后的 offset
另外所有的 VMA 地址未初始化,VMA 的值为 64 linux kernel 的用户态虚拟空间的起始地址 0000000000400000
加上入口函数(这里先看做是 main 函数)的偏移量(按页对齐)
1 | ~ objdump -w -h a.o |
重定位(指令修正)
可执行文件中需要重定位的符号的指令地址尚未初始化,先查看需要充定位的符号(UND 类型)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16~ readelf -s a.o
Symbol table '.symtab' contains 12 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS a.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 6
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 46 FUNC GLOBAL DEFAULT 1 main
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND shared // UND 表示未定义的符号,需要重定位
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND swap // 同上
查看需要重定位的符号
1 | ~ readelf -r a.o |
查看 a.o 的汇编代码,看看未重定位前的指令地址1
2
3
4
5
6
7
8
9
10
11
12
13
14~ objdump -d a.o
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
f: 48 8d 45 fc lea -0x4(%rbp),%rax
13: 48 8d 35 00 00 00 00 lea 0x0(%rip),%rsi # 1a <main+0x1a> // shared 变量引用, (00 00 00 00) 0x0 未赋值,
1a: 48 89 c7 mov %rax,%rdi // 0x1a 是下一条指令偏移,lea 指令压入下一条指令地址
1d: b8 00 00 00 00 mov $0x0,%eax
22: e8 00 00 00 00 callq 27 <main+0x27> // callq 调用 swap 函数,0x27 是下一条指令地址
27: b8 00 00 00 00 mov $0x0,%eax
2c: c9 leaveq
2d: c3 retq
查看链接完成后的指令地址1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20~ objdump -d ab
0000000000401000 <main>:
401000: 55 push %rbp
401001: 48 89 e5 mov %rsp,%rbp
401004: 48 83 ec 10 sub $0x10,%rsp
401008: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
40100f: 48 8d 45 fc lea -0x4(%rbp),%rax
401013: 48 8d 35 e6 2f 00 00 lea 0x2fe6(%rip),%rsi # 404000 <shared> // 0x2fe6 = 0x404000 - 0x40101a
40101a: 48 89 c7 mov %rax,%rdi
40101d: b8 00 00 00 00 mov $0x0,%eax
401022: e8 07 00 00 00 callq 40102e <swap> // e8 00 00 00 00 -> e8 07 00 00 00; 0x7= 0x40102e - 0x401027
401027: b8 00 00 00 00 mov $0x0,%eax
40102c: c9 leaveq
40102d: c3 retq
000000000040102e <swap>:
40102e: 55 push %rbp
40102f: 48 89 e5 mov %rsp,%rbp
401032: 48 89 7d f8 mov %rdi,-0x8(%rbp)
401036: 48 89 75 f0 mov %rsi,-0x10(%rbp)
common块之强弱符号
强符号:函数和已初始化的全局变量为;弱符号:未初始化的全局变量
1 | extern int ext; |
多个文件中出现对同一个文件的定义,比如
1 | /* a. c */ | /* b.c */ |
- 多个强符号冲突,编译失败
- 强符号和弱符号同时定义,选强符号
- 多个弱符号,选类型最大的弱符号
- 定义弱引用,编译时不会报错,运行时报错,可用于链接库函数(比如程序是否支持多线程版本 ‘-lphread’)
- 使用 ‘-fno-common’ 禁用弱引用
全局构造和析构
main 函数只是编写代码的入口,实际程序运行的入口是 _start,c++ 使用特殊的 Section 控制全局构造和析构
- .init 构成进程的初始化代码,在 main 函数之前调用
- .fini 构成进程的终止代码,在 main 函数退出后执行
静态库链接
静态库是一组目标文件的集合,基本上其中的一个目标文件只包含一个函数,链接时从库中找到具体的函数实现链接成可执行文件
1 | ~ ar -t /usr/lib/libc.a | grep printf |
如何不使用 # include <stdio.h> 实现 hello.c 中对标准库中 printf 函数的引用
1 | /* hello.c */ |
1 | ~ ar -x /usr/lib/libc.a -> 得到 printf.o 目标文件 |
链接成可执行文件需要的库和目标文件
- crt1.o
- crti.o
- crtbeginT.o
- libgcc.a
- libgcc_eh.a
- libc.a
- crtend.o
- crtn.o
crt1.o、crti.o 和 crtn.o 均是 glibc 运行库启动文件的一部分,运行库部分讲解!!
静态链接示例
静态链接的一个例子,代码和分布
1 | #include <stdlib.h> |
1 | ~ readelf -W -S SectionMapping.elf | column |
静态链接内存映射
查看编译好的 elf 文件的 Segment(将 Section 合并得到 Segment) 信息
1 | ~ readelf -W -l SectionMapping.elf |
程序运行起来后的实际内存映射情况
1 | ~ ./SectionMapping.elf & |
动态链接
什么是动态链接
为什么需要动态链接?
- 静态链接浪费内存空间,对任何公共库函数每个函数都要链接进可执行文件
- 不利于程序的开发和发布,任务静态库更新后,可执行文件需要重新编译
什么是动态链接?
- 程序的模块分隔开,形成独立的文件,不再将他们链接在一起;等程序运行时链接需要的模块
- program1 和 program2 都依赖 lib.so
- program1 运行时发现依赖 lib.so,操作系统将 lib.so 加载至内存,开始链接过程(符号解析、地址定位等
- 运行 program2,加载 program2 是发现其依赖 lib.so,而此时内存中已经有 lib.so 的 副本,则不需要重新加载,只需要链接 program2 和 lib.so
动态链接优势?
- 节省内存
- 减少物理页面的换入和换出
- 增加 cpu 缓存命中率
- 动态的加载各种程序模块(插件开发)
缺点?
- 动态链接的版本不一致,api 接口变动等,导致程序不能运行 (DLL Hell)
- 程序加载时需要代码和数据的重定位(GOT 定位),加上间接寻址,导致程序的运行速度变慢(启动速度)
地址无关代码
编译时指定 -fPIC 可让动态库编译成地址无关(-fpic 和 -fPIC 功能一致,但包小,会出现兼容问题,一般使用 -fPIC);
从静态链接的链接过程中,我们也可以按照静态链接的方式链接动态库,对动态链接中的绝对地址做基址重置;但做基址重置时基址是调用该库的程序的基址,
比如 program1 调用库的需要基址重置修改库中的指令地址,而 program2 调用库也需要修改指令地址;
这样 program1 和 program2 需要自己维护各自的库指令和数据,失去了动态链接的意义。
地址无关:把指令中需要被修改的部分分离出来,跟数据块放在一起,指令部分可以保持不变,数据部分可以再进程中拥有自己的副本。
共享库中地址引用的方式:
- 模块内部调用和跳转:调用函数和调用者在同一个模块,位置相对固定,使用相对地址调用或寄存器相对调用
- 模块内部数据访问:.text 和 .data 的相对位置也是固定的,也可以使用相对地址调用
- 模块间数据访问和模块间调用和跳转
1 | static int a; |
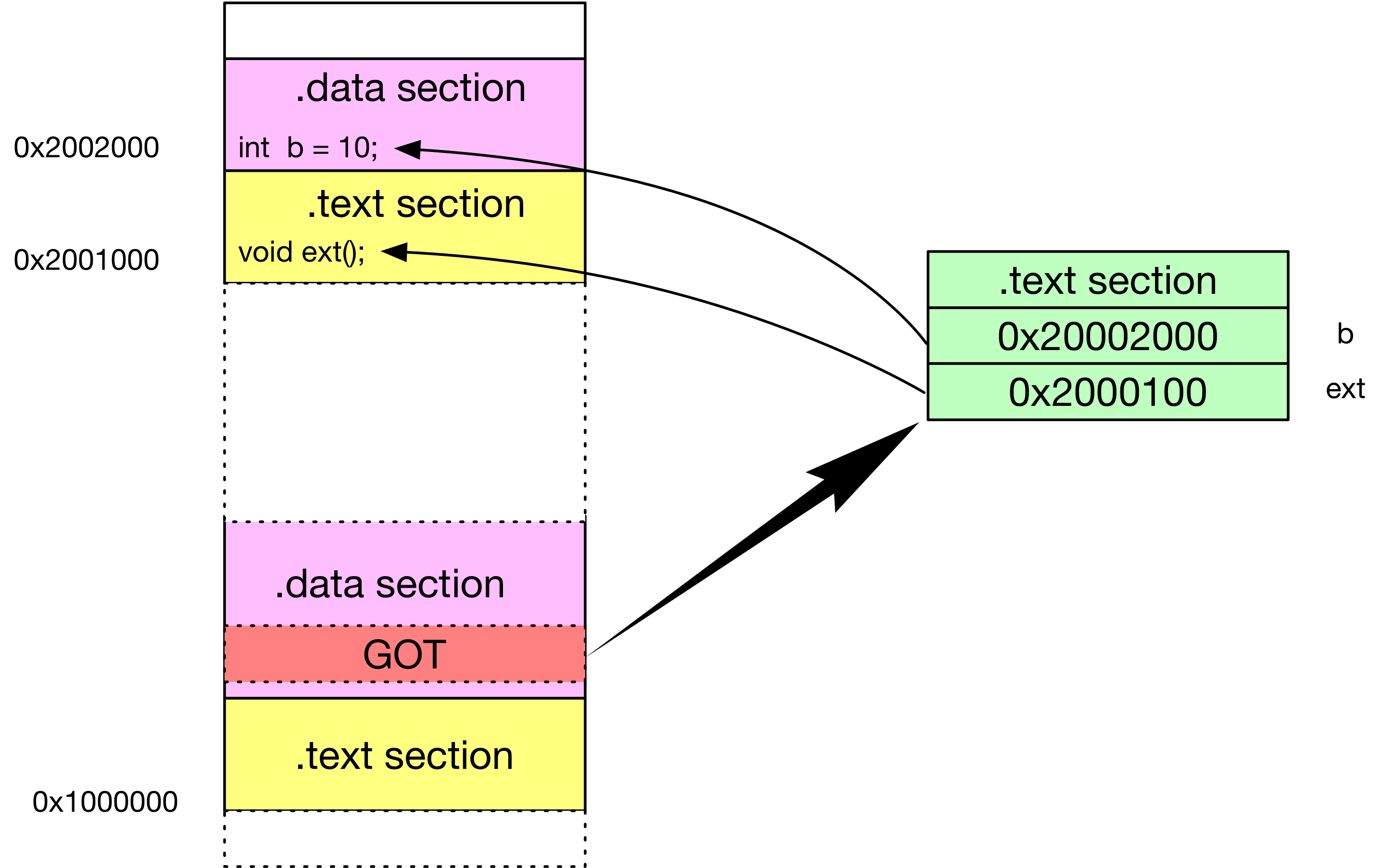
代码中 b 和 ext 的目标地址需要等到装载时才能决定,引入 GOT 表( GLOBAL Offset Table),GOT 表存储在 .data 字段,那么 GOT 表和代码段的相对位置可以固定
GOT 表存存储需要访问的外部变量的地址,则通过一次间接寻址可以获取 b 的实际地址;但编译时是 GOT 表中的对应项是 0,在程序加载时确定外部模块的地址后才能由动态链接器填入具体值
GOT 实现原理
延迟绑定 PLT
动态链接相对灵活,却牺牲一部分性能
- 全局和静态数据的间接寻址
- 模块间调用的GOT重定位; 动态链接是运行时完成,寻找并装共享对象,进行符号地址重定位
在程序执行前,动态链接会耗费时间解决模块之间的函数引用符号的查找和重定位,然后很多函数可能很少用到,如错误处理函数。 ELF 采用延迟绑定(lazing binding)
, 当函数第一次被用到是才进行绑定,如果没用用到就不绑定。ELF 使用 PLT (procedure linkage table)来实现;在 GOT 实现中,外部变量的引用的间接寻址的值由链接器加载时填入,使用 PLT 可以延迟这个过程。
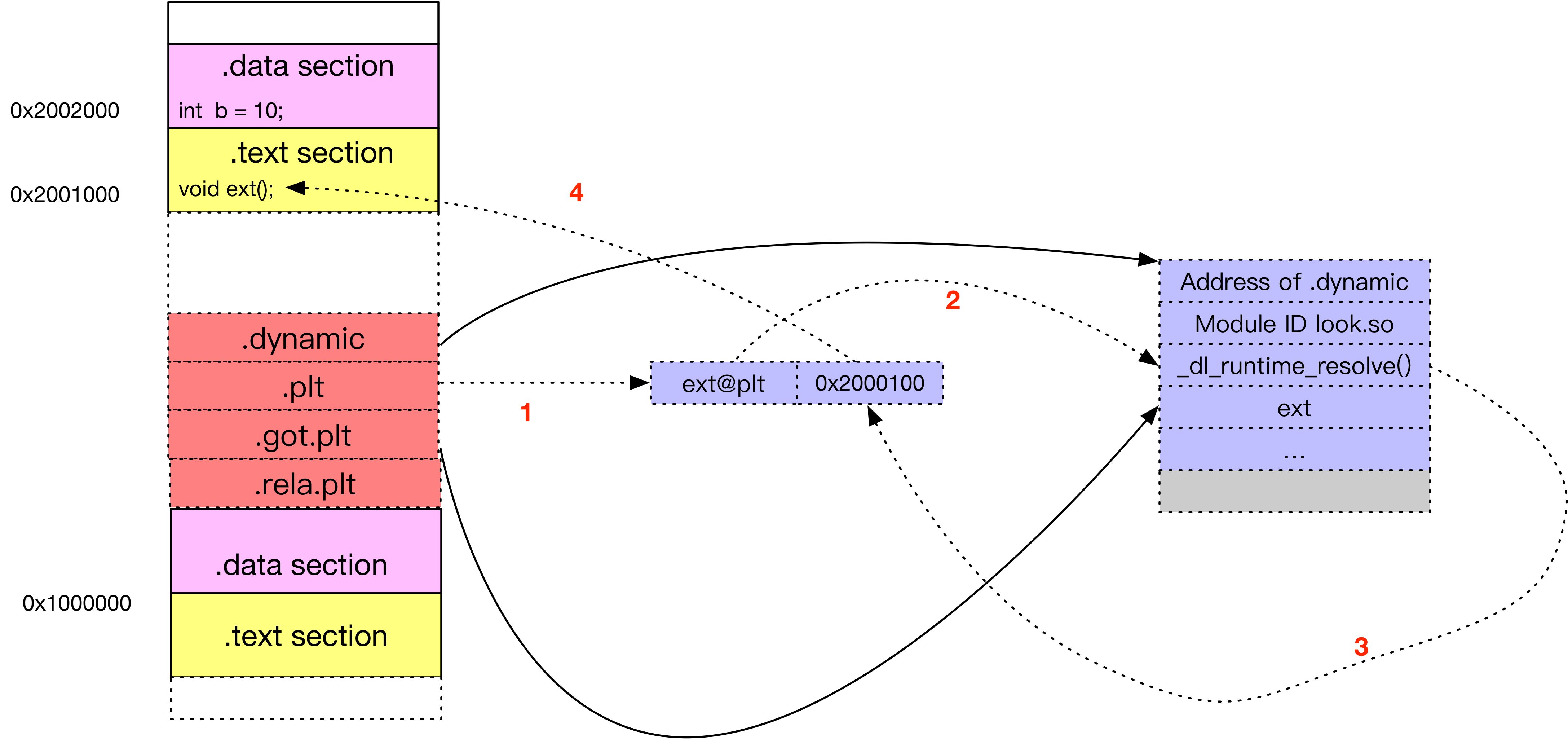
动态链接结构
- .interp 共享库使用的解释器,一般为 /lib/ld-linux.so
- .dynampic 保存动态链接需要的用到的信息;动态链接符号地址,动态链接字符串地址,重定位表入口等
- .dynsym 保存于动态链接相关的符号
- .symtab 保存所有的符号
- .rela.dyn 对数据引用修正,修正位置位于.got
- .rela.plt 对函数引用修正,修正位置位于 .got.plt
动态链接过程
- ld-linux.so 自举
- 装载共享对象
- 重定位和初始化
显示运行时链接
- dlopen
- dlsym
- dlerror
- dlclose
共享库的组织
命名规范1
libname.so.x.y.z
lib 是前缀,中间是库名字
- x 主版本号 重大升级,不同主版本号不兼容
- y 次版本号,增量升级,增加新接口,保持原来符号不变
- z 发布版本号,错误修正,性能改进,不添加任何新接口
so-name 机制
每个共享库都有一个 so-name, 去掉次版本号和发布版本号,共享库 /lib/libfoo.so.2.6.1 对应的 so-name 为 /lib/libfoo.so.2 的软链接
环境变量
- LD_LIBRARY_PATH 设置搜索路径,调试动态库
- LD_PRELOAD 预先加载覆盖后加载的共享库,用于测试
- LD_DEBUG 打印调试信息,打印装载过程
实战
- segfault dmseg
- 错误线索
- 定位步骤
segfault dmesg
戳我!segfault 产生时会在系统的日志中记录错误信息,可以用 dmesg 查看
1 | ~ dmesg | grep testp |
testp[19288]是发错段错误的PIDsegfault at 0表示程序访问地址0是发生了段错误;地址0可能访问了空指针。ip 0000000000401271是指令之指针(instruction pointer),在 64-bit x86 下对应的寄存器为%ripsp 00007fff2ce4d210是栈指针(stack pointer), 在 64-bit x86 下对应的寄存器为%rsperror 4是 16 进制的错误码; 一般情况下至少为 4 表示是用户态的错误;4 表示读一个未映射的内存(unmapped area),6(4+2)表示写一个未映射的内存in testp[400000+98000]段错误的程序是testp, 其ip所在的虚拟地址范围为0x400000 ~ 0x400000+0x98000, 0x98000 表示是该程序映射的大小
错误线索
curl
1
2
3
4
5
6
7
8
9
10
11
12
13vagrant@archlinux:~/nos-openresty master ✗ curl -v 'http://127.0.0.1:1989?ip=121.193.184.2'
* Rebuilt URL to: http://127.0.0.1:1989/?ip=121.193.184.2
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to 127.0.0.1 (127.0.0.1) port 1989 (#0)
> GET /?ip=121.193.184.2 HTTP/1.1
> Host: 127.0.0.1:1989
> User-Agent: curl/7.59.0
> Accept: */*
>
* Empty reply from server
* Connection #0 to host 127.0.0.1 left intact
curl: (52) Empty reply from servererror log
1
2
32019/11/21 09:57:43 [notice] 14393#14393: signal 17 (SIGCHLD) received from 14394
2019/11/21 09:57:43 [alert] 14393#14393: worker process 14394 exited on signal 11 (core dumped)
2019/11/21 09:57:43 [notice] 14393#14393: start worker process 14566demsg
1
[37568.563121] nginx[14394]: segfault at a ip 00007f10ef0973fd sp 00007ffc1688f480 error 6 in lipip.so[7f10ef096000+2000]
这里的
lipip.so[7f10ef096000+2000]已经表明了是 lipip.so 中的异常,如果没有标识出是lipip库的异常,可以根据 maps 看是共享库还是程序本身的异常。7f10ef096000+2000中
7f10ef096000是基址偏移量,+2000标识这个 map 对应的大小。
定位步骤
先看下 lipip.so 有没有 dwarf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30vagrant@archlinux:~/reading/lipip develop ✗ readelf -W -S lipip.so
There are 35 section headers, starting at offset 0x67d0:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .note.gnu.build-id NOTE 00000000000001c8 0001c8 000024 00 A 0 0 4
[ 2] .gnu.hash GNU_HASH 00000000000001f0 0001f0 000050 00 A 3 0 8
......
[11] .text PROGBITS 00000000000010e0 0010e0 0008b2 00 AX 0 0 16
......
[20] .got PROGBITS 0000000000201fe0 001fe0 000020 08 WA 0 0 8
[21] .got.plt PROGBITS 0000000000202000 002000 000138 08 WA 0 0 8
[22] .data PROGBITS 0000000000202140 002140 000060 00 WA 0 0 32
[23] .bss NOBITS 00000000002021a0 0021a0 000008 00 WA 0 0 1
[24] .comment PROGBITS 0000000000000000 0021a0 00001a 01 MS 0 0 1
[25] .debug_aranges PROGBITS 0000000000000000 0021ba 000090 00 0 0 1
[26] .debug_info PROGBITS 0000000000000000 00224a 001830 00 0 0 1
[27] .debug_abbrev PROGBITS 0000000000000000 003a7a 000503 00 0 0 1
[28] .debug_line PROGBITS 0000000000000000 003f7d 00046f 00 0 0 1
[29] .debug_str PROGBITS 0000000000000000 0043ec 0005a6 01 MS 0 0 1
[30] .debug_loc PROGBITS 0000000000000000 004992 000ec9 00 0 0 1
[31] .debug_ranges PROGBITS 0000000000000000 00585b 000060 00 0 0 1
[32] .symtab SYMTAB 0000000000000000 0058c0 0009a8 18 33 57 8
[33] .strtab STRTAB 0000000000000000 006268 00040e 00 0 0 1
[34] .shstrtab STRTAB 0000000000000000 006676 000153 00 0 0 1如果没有
.debug开头的 section,说明没有 dwarf 符号,需要到编译机-g重新编译。看程序段的地址分配
1
[11] .text PROGBITS 00000000000010e0 0010e0 0008b2 00 AX 0 0 16
范围为
0x00000000000010e0 ~ 0000000000001992(0x00000000000010e0+0x0008b2)查看 segfault 错误信息
1
segfault at a ip 00007f10ef0973fd sp 00007ffc1688f480 error 6 in lipip.so[7f10ef096000+2000]
用 ip 值减去基址偏移:
1
0x00007f10ef0973fd - 0x7f10ef096000 = 0x13fd
用 addr2line 工具定位错误行号
1
vagrant@archlinux:~/reading/lipip develop ✗ addr2line -e lipip.so 0x13fd
查看代码行号
1
2
3
4
5
6
7
896 ...
97 if (s <= e) {
98 lua_pushstring(L, s);
99 lua_rawseti(L, -2, i);
100 }
101
102 int *p = 10;
103 *p = 0; // 修改栈上值
运行库
启动函数
main 函数并非程序的起点: _start -> _libc_start_main (.init -> rtld_fini -> .fini)-> main -> exit
- crt1.o 是程序的真正入口函数 _start,由它调用
_libc_start_main,包含基本的启动、退出代码。开始叫 crt.0,为强调是链接输入第一个文件更名为 crt0.o, 后来为了兼容 .init 和 .fint 又升级为 crt1.o - 由于c++ 出现和 elf 改进,必须在 main 函数之前全局/静态对象的构造,glibc 库在每个目标文件中引入了 .init 和 .fint 段; crti.o 和 crtn.o 帮助 .init 和 .fint 完成构造和清理相关工作
- crti.o 和 crtn.o 提供了 .init 和 .finit 的机制, 实际完成构造和析构的是 crtbeginT.o 和 crtend.o
运行库
运行库(runtime library), C 运行库 CRT
- 启动与退出
- 标准函数(标准输入、输出;文件;字符;字符串..)
- I/O
- 堆 / 特殊实现 / 调试
标准函数变长实现
1 | #define va_list char* |
1 | #include <stdio.h> |
为什么只有 cdcel 可以实现变长参数,而 stdcall 不能实现变长参数?
CRT 与多线程
多线程版本运行库中,线程不安全函数会自动加锁,包括 malloc, printf 等
errno
# define errno (*__errno_location())不同的__errno_location返回地址不同线程特有的只是栈(出入栈频繁,不可控)和寄存器(数量少),使用
Thread Local Storage1
__thread int number`
系统调用与API
什么是系统调用?
程序运行时,其本身是没有多少æ利去访问系统资源(文件、网络、io 等)的,因系统有限的资源可能被多个不同的程序同时访问,需要系统级的保护和协调。
linux 系统调用
使用通用寄存器传递参数,EAX 寄存器传递系统调用号(例如0x80),EAX=1(exit); EAX=2(fork); EAX=3(IO read); EAX=4(IO write);
系统调用可以绕过 glibc 直接使用(性能考虑)
linux 为了系统的稳定性和安全性分为两种特权级别:用户态和内核态,系统调用运行在内核态,而要使用系统调用时必须有用户态切换到内核态,切换的过程是通过中断实现。
中断
中断是一个硬件或软件发出的请求,要求 cpu 暂停当前的工作去处理其他事情;
中断有两个属性,中断号和中断处理程序,而中断号是有限的,所以 linux 采用中断号和系统调用号组合来实现不通的系统调用
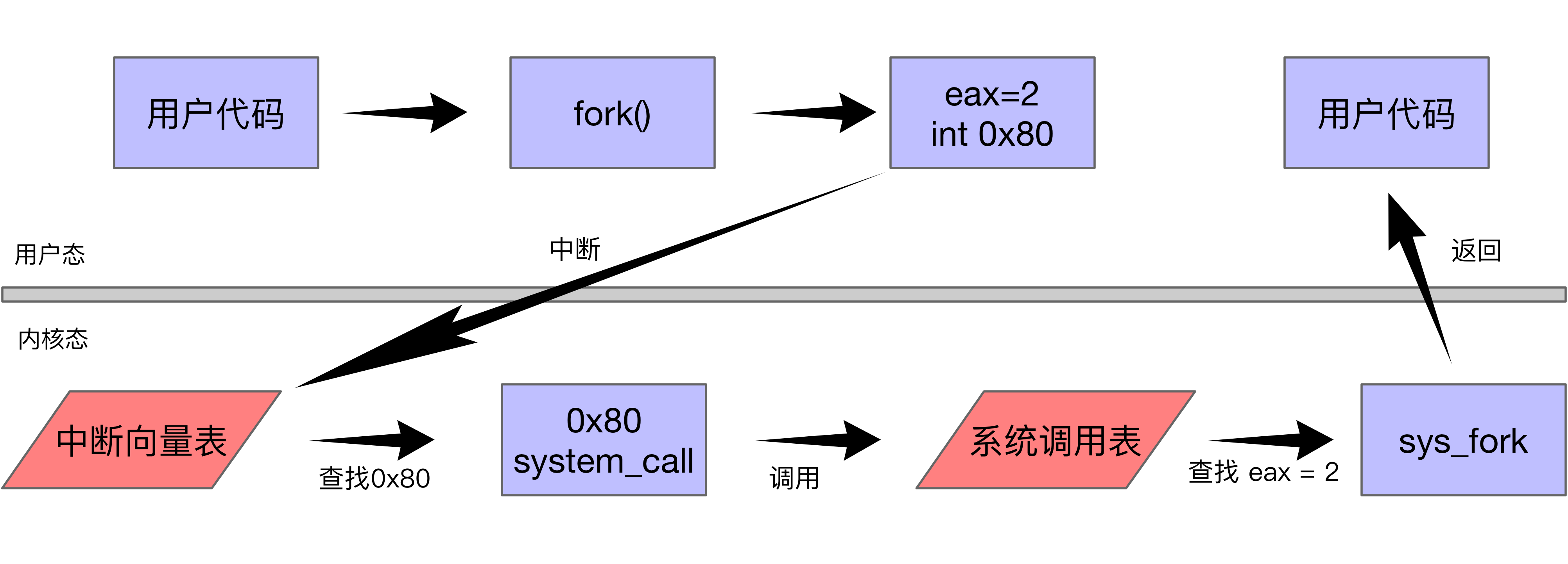
- 触发中断
- 切换堆栈(用户态和内核态使用不同的栈,切换至当前栈(ESP 寄存器的值)至内核态的栈)
- 中断处理程序